
DataBusiness Intelligence as a service — a journey

Txus Bach
Whoever your customers are, they all want to derive value from their own data. In fact, that’s probably why they signed up to your SaaS in the first place —they expect you to organize, enrich, or otherwise utilize their data in ways they can’t easily access by themselves and bring the juicy fruits back to them.
However, no matter how rich your UX is, or how plentiful its insights are, your product only tells part of the story through data. Many customers, while enjoying the story, demand access to the raw data points as well.
Those customers have questions that your product can’t currently answer, but with access to the data you organized for them, they could answer them on their own.
Are you ready to give your customers the keys to the kingdom? Email them your database credentials, or maybe ask them politely to only look at their own data? Perhaps one day we have something like that, but not right now.
At Factorial, like at so many multi-tenant SaaS, we faced this problem, and we solved it in a couple of iterations.
First iteration: fresh off the database
Our first couple iterations let users query data by building data structures that we translated to SQL, to be ran directly against our production database. Even though it worked, there was a high impedance mismatch between our users’ mental models and the database structure, so the generated queries were unnatural and costly.
Second iteration: an in-memory sandbox
Our second iteration was to first abstract the data contract itself. Instead of serving raw data to the customers from our database tables, we wanted to model our data to make them more denormalized and easier to work with. This also allowed us to create higher-level models that represent more abstract concepts. For example, from lower-level models such as employees, shifts, and leaves, we can easily model employee_presences, which succinctly expresses when an employee is currently doing their shift, or on some kind of leave.
Due to the fact that some of this modeling is rather complex, with recursive relationships and quite a lot of edge cases, we decided to go with Ruby —the language of our backend— instead of plain SQL. We also decided to compute those models at read-time, which enabled us to apply authorization and only serve data that the requesting user is allowed to see.
We called those models exposers, and they became our public, access-controlled data API that customers could use.
Querying exposers with SQL
But of course, customers don’t want just a bunch of tables, no matter how much high-level modeling goes into them — they expect a proper query engine to access their data, and especially for power users, SQL is a must.
The solution was, of course, SQLite —the power-horse of flexibility.
Architecture-wise, when a customer’s SQL query came in, we parsed it to extract what tables it was referring to, let’s say employees and shifts. Then, we went ahead and computed those exposers in real time, which gave us two big tables. Next, we spun up an instance of SQLite in memory and had it consume those two tables —then, we sent it the customer query and SQLite solved it, giving us the answer, which we sent back to the client.
To capture this pattern, we wrote and open-sourced TentacleSQL, a service that takes care of all of this for you.
All of this happened in the context of an HTTP request from the client. Latency was unavoidable, but the error rate was low, and life was good.
This design had some very nice strengths:
- Data is access-controlled from its very creation. Cross-tenant or access-control leaks are impossible by design.
- Data is strongly consistent, only computed at query time —customers can be confident they are seeing up-to-date information every time.
- Operationally, it is rather simple. Everything happens in memory, and there are few moving parts.
Growth pains
Later on, as latency was hiking and the error rate was reaching unacceptable levels, we realized we had outgrown the approach. The problems were, as expected, scaling problems.
- For certain customers, computing certain exposers became too memory-intensive, to the point that our server processes would just kill those workers as if they were leaking memory.
- On some occasions where computing, the exposers were perfectly fine, each of those was still a little too big. When feeding all the data to the in-memory SQLite, it would blow up with memory errors as well.
- Queries that handled a sizable amount of data ended up timing out, even if they would have eventually been completed given more time.
In retrospect, we were applying a transactional approach to an analytical problem. We were offering our clients Online Analytical Processing (OLAP) of their data, but using a traditional transactional database to fulfill those queries, and serving them strongly consistent data. OLAP workloads are (at least in my experience, as I write this in 2022) incompatible with strong consistency.
Second iteration: an eventually consistent approach
Given the learnings from the first iteration, the high-level approach we settled for was:
- Compute the exposers ahead of time, for each user.
- Dump them into S3 for later consumption with an analytics-friendly database, like AWS Athena.
- When a query comes in, simply ask Athena.
We chose Athena since it’s well suited to online analytical processing —it’s a managed Presto-ish database that can consume JSON files directly from S3.
The first problem to tackle was scaling the computation of the exposers. Even for a single user, some exposers were simply too memory intensive. As an example, for some of our blue-collar customers, the number of shifts their staff performs over a year can already be hard to compute in a single sitting.
We solved this by letting each exposer partition itself so that it can be computed in small bits, incrementally —and thus in parallel too. For querying, we used Athena.
Scaling the exposer computation horizontally
Every exposer’s goal is to generate some dataset. To do that, it usually starts from some root entity, often the employees of the company then proceed to calculate things relative to each of those root entities, for example, the shifts they’ve performed.
The assumption here is that, in most cases, the cardinality of that root entity has a linear impact on how much computation we need to do. In concrete terms, we are assuming that shifts, for example, are evenly distributed among employees.
As long as that is the case, we could split a single exposer into N mini-batches, each of which computes the shifts of a few employees at a time. These are highly parallelizable, as there isn’t even any synchronization point —each minibatch ends up as its own file in S3, independent of any other file.
Crucially, memory is not a problem anymore, since we can make the chunks small, and we can trade off time (how long it takes to compute all the exposers for a company) for $$$ (how many parallel workers we can keep hammering away at the problem).
Querying the data securely and efficiently
AWS Athena is simpler than it looks on the surface. It loads the contents of one or more partitions (S3 folders) into memory and computes an SQL query over that.
This means that, if you keep all your data in a single partition, you’ll find yourself loading the entire S3 folder for any query, every time. Thus, one of the keys to good performance in Athena is strategic partitioning.
The exposers we ship to S3 are highly partitioned, not only by date of ingestion, which gives us time travel and auditing for free but up to the ID of the user who’ll query the data.
We also use AWS Athena’s partition projection to eliminate any synchronization points. No MSCK REPAIR TABLE is needed —as soon as the data is in S3, it’ll be available for queries.
This way, when a user query comes in, we know that we only read exactly as little data as we need to fulfill the query, and there is no chance for a user-submitted query to accidentally read data intended for other users.
Translating queries to point to the right data
A detail that may have surprised you while reading this is that customers write their own SQL queries.
From their perspective, they write SELECT * FROM employees, but employees can’t simply be a table in Athena — we want to serve this customer:
- All the employees in their company, not anyone else’s company
- All the employees they can see, given their permissions in that company
- The latest version of those employees, given the latest ingestion date
To achieve that, we rewrite the queries dynamically by:
- Parsing the query and identifying which tables are being queried, for example,
employeesandshifts. - Writing a prelude for the query with a CTE (Common Table Expression) per table, like
WITH employees AS (SELECT * FROM ...). In the CTEselectclause we can point to the latest version of theemployeesdata, filter the data by the user’s company and then filter further by the user’s permissions.
This way, customers can write natural SQL queries, and at query time we rewrite and translate them, send them to Athena and get the right results back.
Conclusion
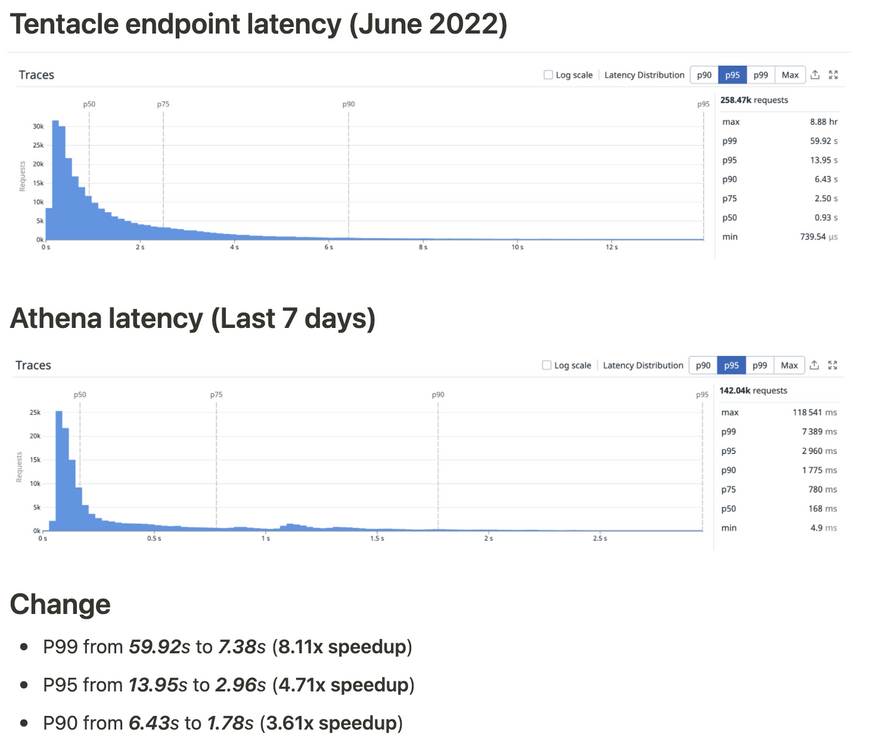
The new Athena-based system was rolled out recently, improving P95 latencies several-fold, and enabling previously uncomputable queries to run in predictable time.
In exchange, we gave up strong consistency and added extra operational costs, but it has been well worth it —as reported not only by our metrics but also in interviews with our customers. Here’s a breakdown of the latency distributions for the first iteration (TentacleSQL-based) versus the Athena-based system.

Small data is easy, and big data has a thriving ecosystem behind it. When you find yourself in the under-researched space of awkwardly-sized data —borrowing the term from Élise Huard—, you need a bit more engineering and tinkering to get things to work nicely, but it can be done!